
一、写在前面
上篇分析了快递包裹数据的基本规律。然后我就在想:这些规律能不能用来预测?
今天打算用LaDe真实数据,跑ARIMA、Prophet、LSTM三种方法,看看准确率能到多少。
但数据一上手,就发现不对劲...
二、数据质量检查
2.1 第一个异常:包裹量骤降
按照标准流程,先加载5城市的数据,做个基础统计。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
cities = {
'delivery_sh.csv': '上海',
'delivery_hz.csv': '杭州',
'delivery_cq.csv': '重庆',
'delivery_yt.csv': '烟台',
'delivery_jl.csv': '吉林'
}
all_data = []
for filename, city in cities.items():
df = pd.read_csv(f'data/raw/delivery/{filename}')
df['city'] = city
all_data.append(df)
print(f"✓ 已加载 {city} 数据: {len(df):,} 条记录")
df_all = pd.concat(all_data, ignore_index=True)
# 转换时间字段
df_all['ds'] = df_all['ds'].astype(str).str.zfill(4)
df_all['ds'] = pd.to_datetime('2022' + df_all['ds'], format='%Y%m%d')
输出:
✓ 已加载 上海 数据: 1,483,864 条记录
✓ 已加载 杭州 数据: 1,861,600 条记录
✓ 已加载 重庆 数据: 931,351 条记录
✓ 已加载 烟台 数据: 206,431 条记录
✓ 已加载 吉林 数据: 31,415 条记录
数据加载没问题。接下来看看每天的包裹量:
# 合并后的总体情况
daily_data = df_all.groupby('ds').size().reset_index(name='orders')
daily_data = daily_data.set_index('ds').sort_index()
print("【5城市合并数据】")
print(f"数据范围: {daily_data.index.min()} 到 {daily_data.index.max()}")
print(f"总天数: {len(daily_data)}")
print(f"日均包裹: {daily_data['orders'].mean():.0f}")
print(f"最大值: {daily_data['orders'].max():,}")
print(f"最小值: {daily_data['orders'].min():,}")
# 看看包裹量最少的几天
print("\n包裹量最少的10天:")
print(daily_data.nsmallest(10, 'orders'))
输出:
5城市合并数据概览:
数据范围: 2022-05-01 到 2022-10-31
总天数: 184
日均包裹: 24536
最大值: 49,408 (2022-10-26)
最小值: 10,296 (2022-05-03)
包裹量最少的10天:
2022-05-03: 10,296单
2022-05-04: 10,880单
2022-05-08: 11,079单
2022-05-09: 11,350单
2022-05-12: 11,991单
2022-05-10: 12,043单
2022-05-14: 12,049单
2022-05-22: 12,067单
2022-05-11: 12,185单
2022-05-23: 12,208单
包裹量最少的10天全是5月!而且最低只有10,296单,不到日均值的一半。
是数据采集问题?还是业务真的暴跌了?
2.2 可视化确认
画张图看看趋势:
plt.figure(figsize=(14, 6))
plt.plot(daily_data.index, daily_data['orders'], linewidth=1.5)
plt.axhline(y=daily_data['orders'].mean(), color='green', linestyle='--',
label=f'均值 {daily_data["orders"].mean():.0f}单', alpha=0.6)
plt.axvspan(pd.Timestamp('2022-05-01'), pd.Timestamp('2022-05-31'),
alpha=0.15, color='red', label='5月异常')
plt.title('5城市合并日包裹量(2022年5月1日-10月31日)', fontsize=14)
plt.ylabel('包裹量')
plt.xlabel('日期')
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('daily_volume_anomaly.png', dpi=150)
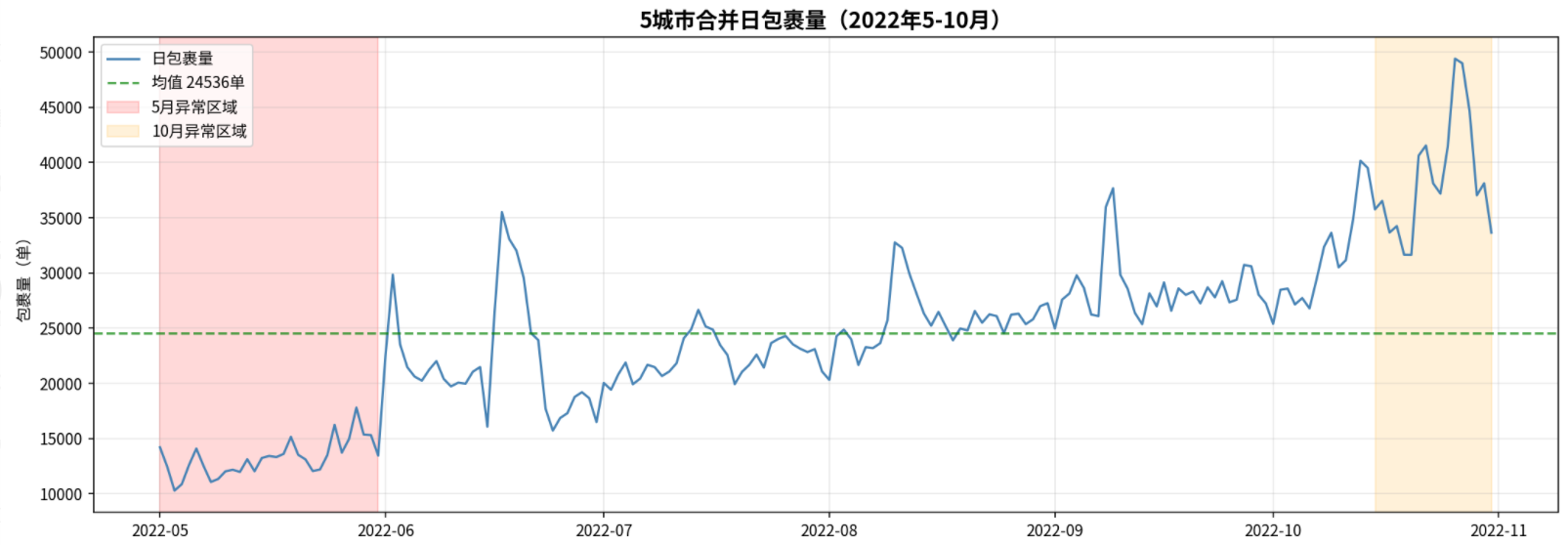
图上看得更清楚:5月是个大坑,一直到6月才爬上来。
这到底发生了什么?
三、跨城市对比
如果是数据采集故障,应该所有城市都异常。如果只有个别城市异常,那就是业务问题。
3.1 逐城市分析
先看看每个城市的情况:
for filename, city in cities.items():
df_city = df_all[df_all['city'] == city]
daily_city = df_city.groupby('ds').size().reset_index(name='orders')
daily_city = daily_city.set_index('ds').sort_index()
print(f"\n【{city}】")
print(f" 数据范围: {daily_city.index.min()} 到 {daily_city.index.max()}")
print(f" 总天数: {len(daily_city)}")
print(f" 日均包裹: {daily_city['orders'].mean():.0f}")
print(f" 最大值: {daily_city['orders'].max():,}")
print(f" 最小值: {daily_city['orders'].min():,}")
# 显示包裹量最少的3天
print(f" 包裹量最少的3天:")
for date, row in daily_city.nsmallest(3, 'orders').iterrows():
pct = row['orders'] / daily_city['orders'].mean() * 100
print(f" {date.strftime('%Y-%m-%d')}: {row['orders']:,}单 (日均的{pct:.1f}%)")
输出:
【上海】
数据范围: 2022-05-01 到 2022-10-31
总天数: 184
日均包裹: 8,064
最大值: 17,381
最小值: 438
包裹量最少的3天:
2022-05-13: 438单 (日均的5.4%)
2022-05-01: 466单 (日均的5.8%)
2022-05-15: 466单 (日均的5.8%)
【杭州】
数据范围: 2022-05-01 到 2022-10-31
总天数: 184
日均包裹: 10,117
最大值: 17,800
最小值: 5,953
包裹量最少的3天:
2022-05-03: 5,953单 (日均的58.8%)
2022-05-09: 6,114单 (日均的60.4%)
2022-06-15: 6,210单 (日均的61.4%)
【重庆】
数据范围: 2022-05-01 到 2022-10-31
总天数: 184
日均包裹: 5,062
最大值: 14,172
最小值: 2,281
包裹量最少的3天:
2022-06-15: 2,281单 (日均的45.1%)
2022-08-29: 2,661单 (日均的52.6%)
2022-08-28: 2,675单 (日均的52.8%)
【烟台】
数据范围: 2022-05-01 到 2022-10-31
总天数: 184
日均包裹: 1,122
最大值: 2,252
最小值: 603
包裹量最少的3天:
2022-05-24: 603单 (日均的53.7%)
2022-05-23: 683单 (日均的60.9%)
2022-05-14: 725单 (日均的64.6%)
【吉林】
数据范围: 2022-05-12 到 2022-10-28
总天数: 163
日均包裹: 193
最大值: 434
最小值: 1
包裹量最少的3天:
2022-10-20: 1单 (日均的0.5%)
2022-10-26: 1单 (日均的0.5%)
2022-10-28: 1单 (日均的0.5%)
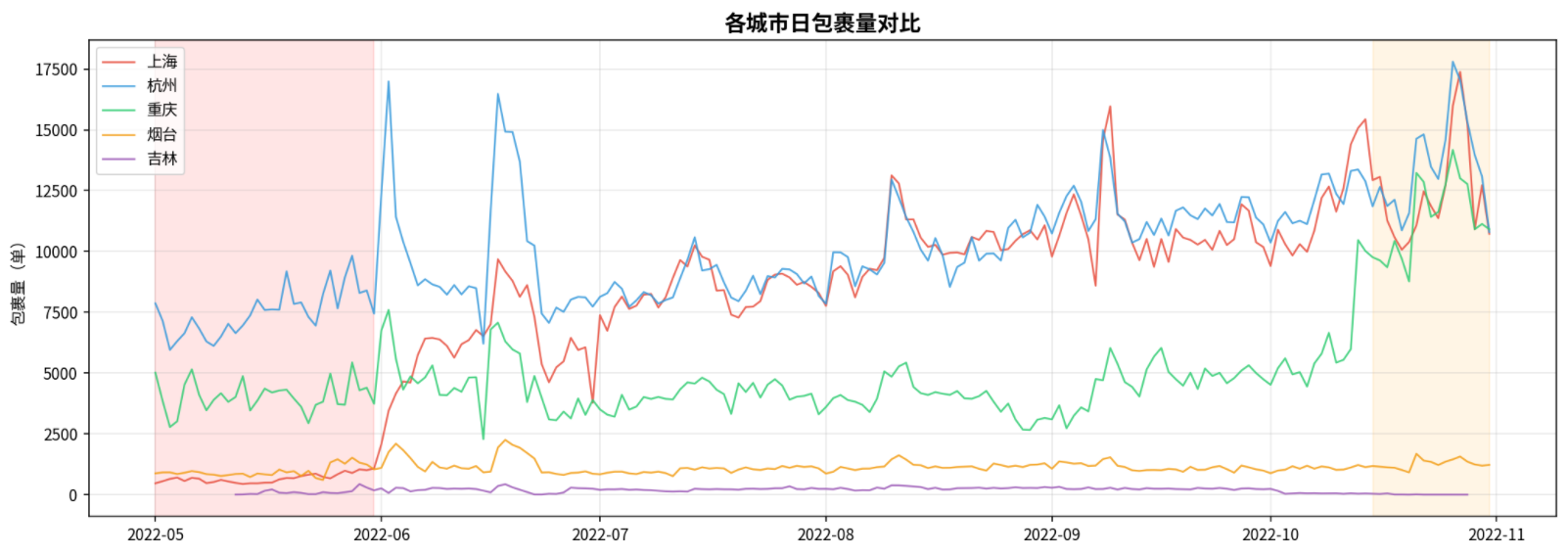
第一个线索:上海5月异常低
上海最低438单(5月13日),是日均8,064单的5.4%!而且包裹量最少的3天全在5月。
第二个线索:吉林10月突变
吉林10月20日之后降到1单,从日均193单骤降到0.5%。
但其他城市呢?杭州、重庆、烟台的最低值都不在5月或10月。
3.2 热力图分析
画个热力图,更直观地看跨城市的异常模式:
# 构建跨城市热力图数据
city_daily = df_all.groupby(['ds', 'city']).size().reset_index(name='orders')
pivot_data = city_daily.pivot(index='ds', columns='city', values='orders')
# 计算每个城市相对于其均值的比率
pivot_ratio = pivot_data / pivot_data.mean()
# 找出异常日期:任一城市低于其均值的30%
anomaly_threshold = 0.3
anomaly_days = pivot_ratio[pivot_ratio.min(axis=1) < anomaly_threshold].index
print(f"发现 {len(anomaly_days)} 个异常日期")
print("(判断标准:任一城市的包裹量 < 该城市平均值的30%)")
# 画热力图
plt.figure(figsize=(20, 6))
sns.heatmap(pivot_ratio.T, cmap='RdYlGn', center=1.0,
vmin=0, vmax=2, cbar_kws={'label': '相对均值比率'},
linewidths=0.5, annot=False)
plt.title('各城市包裹量热力图(相对于均值,2022-05至10月)', fontsize=14)
plt.xlabel('日期')
plt.ylabel('城市')
plt.tight_layout()
plt.savefig('cross_city_anomaly_heatmap.png', dpi=150, bbox_inches='tight')
输出:
发现 55 个异常日期
(判断标准:任一城市的包裹量 < 该城市平均值的30%)
热力图非常直观!
看到两个明显的异常模式:
- 5月上海一片深红(包裹量极低)
- 10月中下旬吉林深红,但其他城市都是深绿(高位)
四、推理真相
现在证据很明显:
4.1 异常模式1:上海5月
- 上海5月深度异常(最低日均5.4%)
- 同期其他城市相对正常(杭州58.8%,烟台53.7%)
- 6月上海快速恢复
4.2 异常模式2:吉林10月
- 吉林10月中下旬骤降(降到0.5%)
- 同期其他4城市正常,甚至更高
这不是数据故障,是真实的业务中断。
4.3 查证新闻
真相1:上海4-5月疫情封控
2022年4-5月,上海因疫情封控,物流基本停摆。
数据验证:
sh_data = city_daily['上海']
sh_may = sh_data.loc['2022-05-01':'2022-05-31']
sh_normal = sh_data.loc['2022-06-15':'2022-09-30']
print(f"上海5月日均: {sh_may['orders'].mean():.0f}单")
print(f"上海正常期日均: {sh_normal['orders'].mean():.0f}单")
print(f"5月相对正常期: {sh_may['orders'].mean()/sh_normal['orders'].mean()*100:.1f}%")
输出:
上海5月日均: 675单
上海正常期日均: 9,367单
5月相对正常期: 7.2%
上海5月包裹量暴跌92.8%!
这完美解释了为什么:
- 5月包裹量骤降
- 只有上海深红
- 6月解封后快速恢复
真相2:吉林10月疫情管控
2022年10月中旬,吉林市再次出现疫情。
验证一下其他城市10月的情况:
oct_late = pivot_ratio.loc['2022-10-15':'2022-10-31']
print("10月中下旬各城市对比(相对各自均值):")
for city in ['上海', '杭州', '重庆', '烟台', '吉林']:
val = oct_late[city].mean()
print(f" {city}: {val*100:.1f}%")
输出:
10月中下旬各城市对比(相对各自均值):
上海: 153.7% (反而更高!)
杭州: 133.4% (反而更高!)
重庆: 223.6% (暴涨!)
烟台: 112.8% (正常)
吉林: 7.6% (崩了)
真相大白:疫情导致两次明显的业务中断。
五、除了疫情,还有什么规律?
虽然有疫情干扰,但数据里应该还有其他规律。我选取6-9月相对正常的数据进行分析。
5.1 规律1:618促销冲击
6月中旬出现巨大尖峰。标记618前后对比:
jun_data = daily_data.loc['2022-06-01':'2022-06-30']
jun_normal = jun_data[~jun_data.index.isin(pd.date_range('2022-06-15', '2022-06-20'))]
jun_618 = jun_data.loc['2022-06-15':'2022-06-20']
print("618促销分析:")
print(f" 6月正常日均: {jun_normal['orders'].mean():.0f}单")
print(f" 618期间日均: {jun_618['orders'].mean():.0f}单")
print(f" 增幅: {(jun_618['orders'].mean()/jun_normal['orders'].mean()-1)*100:.1f}%")
print(f" 618峰值: {jun_618['orders'].max():,}单")
输出:
618促销分析:
6月正常日均: 20,564单
618期间日均: 28,794单
增幅: 40.0%
618峰值: 35,522单
618期间包裹量暴涨40%!
5.2 规律2:整体上升趋势
业务在增长:
x = np.arange(len(normal_period))
y = normal_period['orders'].values
coeffs = np.polyfit(x, y, 1)
daily_growth = coeffs[0]
print("整体增长趋势(6-9月):")
print(f" 每天增长: {daily_growth:.1f}单")
print(f" 月增长: {daily_growth*30:.0f}单")
print(f" 月增长率: {daily_growth*30/normal_period['orders'].mean()*100:.1f}%")
输出:
整体增长趋势(6-9月):
每天增长: 68.9单
月增长: 2,066单
月增长率: 8.4%
业务月增长8.4%,市场在扩张。
六、还要不要做预测?
现在我有了完整的线索:
数据特征:
- 有促销影响(618暴涨40%)
- 有增长趋势(月增8.4%)
- 有疫情黑天鹅(无法预测)
- 只有半年数据(缺年周期)
做预测的挑战:
- 疫情完全随机,不可预测
- 疫情期间的数据不能用来预测正常期
- 半年数据缺少完整年度周期
- 上海5月数据异常,会严重影响模型训练
我的决定:
不做预测了。原因很简单:
- 数据质量决定预测上限:5月数据异常占比太大(1/6的数据),无论用什么模型都会被污染
- 黑天鹅无法预测:疫情这种系统性风险,历史数据学不到
- 半年数据太短:缺少完整年度周期,无法捕捉季节性规律
但深度分析已经给了我们宝贵的洞察。
七、深度分析才是宝藏
虽然不做预测,但通过数据分析,获得了宝贵的业务洞察。
7.1 洞察1:疫情对快递业的非对称影响
- 上海5月:大城市封控,冲击巨大(跌92.8%)
- 吉林10月:小城市局部封控(跌93.3%)
- 杭州5月:虽受影响但较小(仍有58.8%)
启示:
- 大城市网络更脆弱
- 但恢复能力也更强(上海6月下旬已恢复63%)
- 风险分散很重要
7.2 洞察2:促销日影响巨大
618期间增长40%,双11可能更高。
启示:
- 大促前2周开始备人力
- 不能只看历史日均
- 需要促销日历
7.3 洞察3:业务在增长
月增长8.4%,市场在扩张。
启示:
- 人力需求持续增加
- 网点布局要提前规划
- 设备投资回报期缩短
八、总结
这次"预测实战"最大的收获不是模型准确率,而是:
8.1 数据侦探的思维方式
- 从异常出发 → 提出假设 → 交叉验证 → 揭示真相
- 不迷信数据,要质疑数据
- 结合外部信息(新闻、政策)
8.2 真实数据的挑战
- 疫情这种黑天鹅无法预测
- 半年数据有局限性
- 但不妨碍做分析、找规律
8.3 分析比预测更重要
- 预测只是工具,业务洞察才是目标
- 宁可不预测,也不能误导决策
- 诚实对待数据局限,比虚假的高准确率更有价值
下一篇:第10篇:配送路线优化VRP实战