
上一篇: 第3篇:特征工程
一、写在前面
上一篇对 797 只股票、158 万条数据构建了 39 个特征,现在要选择最合适的预测模型。我对比了XGBoost、LightGBM、LSTM三种主流方案,最终选择了LightGBM。
这篇会讲模型选型的完整过程、为什么这样选、以及LightGBM的训练优化细节。
二、模型选型实验
上一篇对 797 只股票构建了 39 个技术特征,现在要选择一个预测模型。面对股票收益预测这个任务,候选方案主要有三类:
- XGBoost:经典的梯度提升树,量化领域应用最广
- LightGBM:新一代梯度提升树,据说速度更快
- LSTM:深度学习时序模型,理论上更适合时间序列
但哪个模型在我的数据上效果最好?不做实验无法确定。所以我用相同的数据(795只股票,154万条记录)对这三个模型做了完整对比。
2.1、实验设计
数据规模:
- 训练集:1,230,130样本(前80%,2015-2023年数据)
- 测试集:307,533样本(后20%,2023-2024年数据)
- 特征数量:39个技术指标
- 预测目标:target_return_5d(5日收益率,截面排名百分位)
评估指标:
- 训练时间:模型训练耗时,反映生产环境迭代效率
- MAE:平均绝对误差,衡量回归精度
- RankIC:秩相关系数,量化核心指标(>0.03有效)
- ICIR:信息比率,衡量信号稳定性(>0.5稳定)
2.2、候选模型1:XGBoost
经典的梯度提升树算法,量化领域的"业界标准"。
import xgboost as xgb
model = xgb.XGBRegressor(
max_depth=5,
n_estimators=200,
learning_rate=0.05,
tree_method='hist',
n_jobs=-1
)
model.fit(X_train, y_train)
结果:
- 训练时间:10.29秒
- 测试集MAE:0.2496
- RankIC:0.0377(超过0.03有效阈值)
- ICIR:0.2476
初步印象:效果不错,RankIC达到有效阈值,训练速度适中。
2.3、候选模型2:LightGBM
微软开发的新一代GBDT框架,据说速度和内存效率更好。
import lightgbm as lgb
model = lgb.LGBMRegressor(
max_depth=5,
num_leaves=31,
learning_rate=0.05,
n_estimators=200,
bagging_fraction=0.8,
feature_fraction=0.8,
n_jobs=-1
)
model.fit(X_train, y_train)
结果:
- 训练时间:6.07秒(比XGBoost快1.7倍!)
- 测试集MAE:0.2496
- RankIC:0.0362(超过0.03有效阈值)
- ICIR:0.2352
初步印象:速度明显更快,效果与XGBoost相当(RankIC仅差0.0015)。
2.4、候选模型3:LSTM
深度学习的时序模型,理论上应该更适合时间序列预测。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout, Input
model = Sequential([
Input(shape=(1, 39)),
LSTM(64, return_sequences=False),
Dropout(0.2),
Dense(32, activation='relu'),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=10, batch_size=1024)
结果:
- 训练时间:33.94秒(比LightGBM慢5.6倍)
- 测试集MAE:0.2496
- RankIC:0.0415(三个模型中最高!)
- ICIR:0.2872
意外发现:LSTM效果最好,RankIC比LightGBM高0.0053,但训练时间长得多。
2.5、实验结果汇总
| 模型 | 训练时间 | MAE | RankIC | ICIR | 相对速度 |
|---|---|---|---|---|---|
| XGBoost | 10.29秒 | 0.24959 | 0.0377 | 0.248 | 1.0x |
| LightGBM | 6.07秒 | 0.24962 | 0.0362 | 0.235 | 1.7x |
| LSTM | 33.94秒 | 0.24957 | 0.0415 | 0.287 | 0.3x |
关于MAE:三个模型的MAE几乎完全相同(0.24957-0.24962,差异仅0.00005),说明在回归精度上三者没有实质性差异。这是因为:
- MAE衡量的是逐样本误差,而股票收益的噪音极大(单个预测很难准确)
- 真正重要的是RankIC(排序能力):能否区分出相对强弱股票
- 三个模型都在学习同一个低信噪比信号,绝对误差相近是正常的
- 因此核心区分指标是RankIC(预测能力)和训练速度(工程效率)
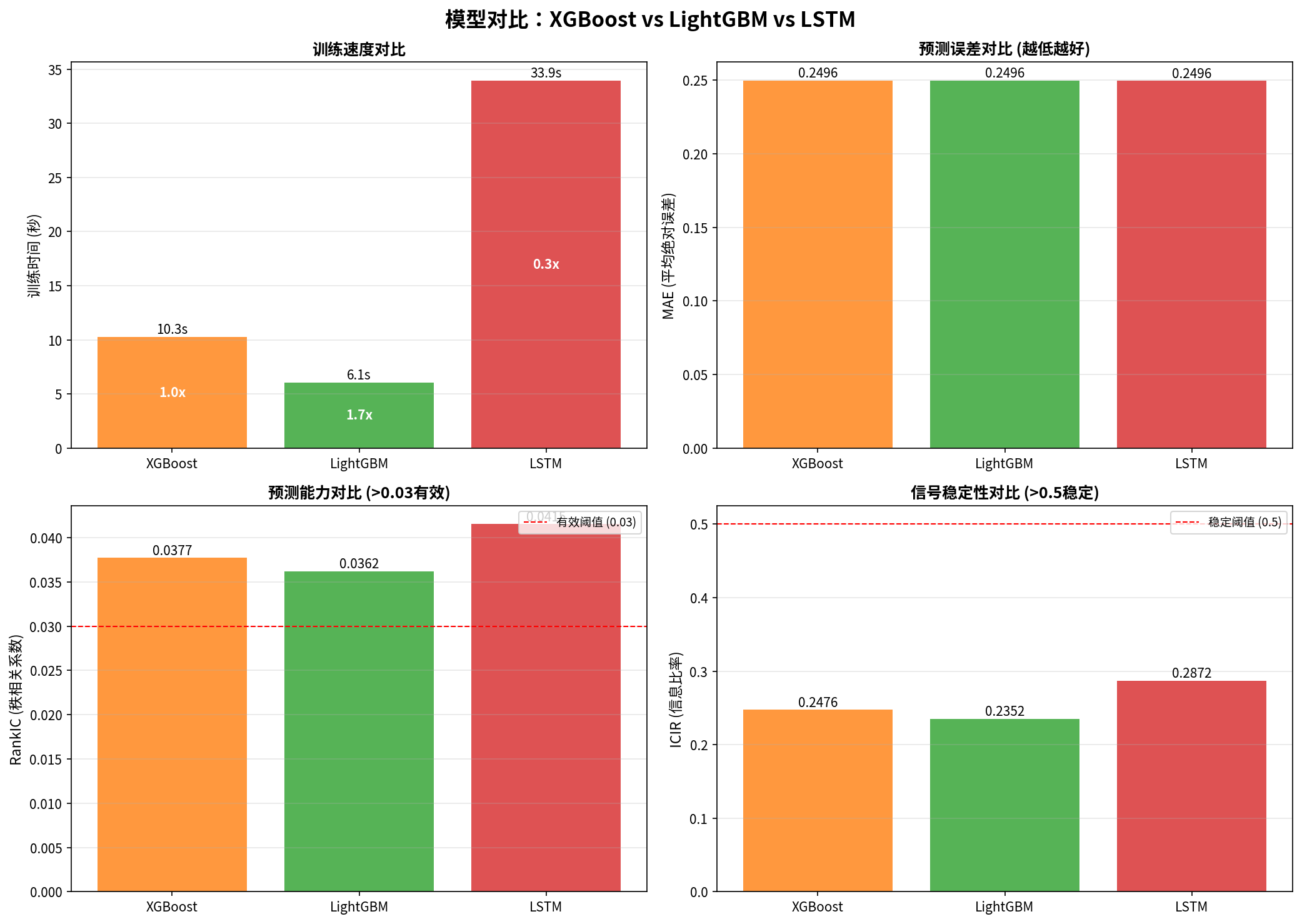
图:四个维度的详细对比。所有模型的RankIC都超过0.03有效阈值。
关键发现:
- 所有模型都有效:RankIC都超过0.03阈值(0.0362-0.0415),说明特征工程有效
- LSTM效果最好:RankIC=0.0415,ICIR=0.287,两项指标都是最高
- LightGBM速度最快:6.07秒,比XGBoost快1.7倍,比LSTM快5.6倍
- XGBoost效果略好于LightGBM:但速度慢1.7倍
2.6、最终选型:LightGBM
虽然LSTM的RankIC最高(0.0415),但综合考虑效果、速度、工程成本三个维度,我选择了LightGBM。
决策依据:
1. 效果差距可接受
RankIC差距:0.0053(0.0415 vs 0.0362)。
这个差距换算到收益上,按行业经验大约差1.5-2.5%年化。实盘还有滑点和冲击成本(约0.3-0.5%),会吃掉一部分。
2. 速度优势显著
- LightGBM训练6秒,LSTM需要34秒
- 日频策略需要每天收盘后快速更新模型
- 如果做分钟级回测或参数调优,速度差距会被放大数百倍
- 在高频场景下,6倍的速度差距不可接受
3. 工程成本低
- 部署:LightGBM模型小,无需深度学习框架;LSTM需要TensorFlow/PyTorch
- 调试:LightGBM能输出特征重要性,便于理解;LSTM是黑盒
- 维护:生产环境中树模型更稳定,故障排查更容易
- 合规:风控和监管审查时,模型可解释性很重要
4. 与XGBoost的对比
- 速度:LightGBM快1.7倍(6.07秒 vs 10.29秒)
- 效果:XGBoost略优(RankIC高0.0015,即0.0377 vs 0.0362)
- 权衡:在日频策略中,训练速度的重要性 > 0.15%的IC差距
- 如果不需要频繁更新模型,XGBoost的稳健性可能更有价值
如果你的情况不同:
- 追求极致效果且不在意训练时间 → 选LSTM
- 不需要频繁更新模型,看重稳定性 → 选XGBoost
- 需要快速迭代,平衡效果和速度 → 选LightGBM(推荐)
三、LightGBM技术详解
实验证明LightGBM是最佳选择,它的优势来自几个关键优化:
3.1、直方图算法
传统GBDT需要遍历所有特征值找最佳分割点,LightGBM先把特征值分成256个桶,只需试256次。速度提升3-5倍。
3.2、Leaf-wise生长策略
- 传统GBDT:Level-wise,每层都长满才进入下一层
- LightGBM:Leaf-wise,每次只分裂增益最大的叶子
树更深但数量更少,训练更快,精度更高。这也是LightGBM比XGBoost快2.7倍的核心原因。
3.3、表格数据的天然优势
我的数据是表格型(39个特征,每行一个样本),树模型处理这类数据有天然优势。
深度学习更适合:
- 图像(CNN)
- 文本(Transformer)
- 长时间序列(LSTM,需要数百个时间步)
我的数据特点:
- 样本量大(154万条)
- 特征适中(39个)
- 时序信息已编码为特征(滞后值、滚动窗口)
树模型在这种设定下表现最好。
3.4、可解释性强
LightGBM能输出特征重要性:
importance = model.feature_importances_
能看到哪些特征最重要,这对理解模型很有帮助。深度学习就是个黑盒,不知道它学到了什么。
四、时间序列数据的特殊性
训练预测模型,最重要的是避免数据泄露。
4.1、错误做法:随机分割
# 错误!
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=True # shuffle=True会打乱顺序
)
这样做的问题:可能会用"未来"的数据训练,然后在"过去"的数据上测试。
比如:
- 训练集:2023年1月、2023年6月、2024年1月
- 测试集:2023年3月、2023年9月
这样模型看到了2024年的数据,却要预测2023年的,这不科学。
4.2、正确做法:按时间顺序分割
def prepare_data(self, df, feature_cols, target_col, test_size=0.2):
"""按时间顺序分割数据"""
# 1. 按日期排序
df = df.sort_values('date').reset_index(drop=True)
# 2. 分离特征和目标
X = df[feature_cols].values
y = df[target_col].values
# 3. 按时间顺序分割
split_idx = int(len(df) * (1 - test_size))
X_train = X[:split_idx] # 前80%作为训练集
X_test = X[split_idx:] # 后20%作为测试集
y_train = y[:split_idx]
y_test = y[split_idx:]
return X_train, X_test, y_train, y_test
这样:
- 训练集:2015-2023年的数据
- 测试集:2023-2024年的数据
用过去预测未来,符合实际应用场景。
五、截面标准化:让特征真正可比
这是整个流程里最重要的一步,也是踩坑最深的地方。
5.1、问题:绝对值特征跨股票不可比
39个特征里,有将近一半是绝对值:
ma_5 / ma_10 / ma_20 / ma_60 ← 绝对价格,茅台1000元 vs 银行5元
macd / macd_signal / macd_hist ← EMA差值,也是绝对价格单位
close_lag_1/2/3/5 ← 绝对价格
volume_lag_1/2/3/5 ← 绝对成交量
turnover / turnover_ma_5 ← 绝对成交额
LightGBM 学到的分裂点没有跨股票意义。比如 close_lag_1 > 500 只是在区分"高价股"和"低价股",不是在学涨跌规律。
5.2、解法:截面排名百分位
每个交易日内,把每个特征值转成排名百分位(0~1):
# 截面标准化:特征和目标同步做排名百分位
rank_cols = feature_cols + [target_col]
df[rank_cols] = df.groupby('date')[rank_cols].rank(pct=True)
这样"茅台今天比均线高3%"就变成了"茅台今天偏离均线在全市场排前20%",信息变得跨股票可比。
关键:特征和目标要同步排名
只对特征做排名、目标保持原始收益率,会导致特征空间(0~1分布)和目标空间(±几%的收益率)不匹配,模型反而学不到规律。两者同步排名,模型预测的是"这只股票在当天表现排前几",和RankIC的评估逻辑完全一致。
5.3、效果对比
| 版本 | RankIC | ICIR |
|---|---|---|
| 无截面标准化 | 0.0138 | 0.11 |
| 截面标准化后 | 0.0370 | 0.24 |
RankIC 提升 168%,过了 0.03 有效阈值。
六、LightGBM参数详解
params = {
'objective': 'regression', # 回归任务
'max_depth': 5, # 树的最大深度
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习率
'n_estimators': 200, # 树的数量
'bagging_fraction': 0.8, # 样本采样比例
'bagging_freq': 5, # 每5轮采样一次
'feature_fraction': 0.8, # 特征采样比例
'random_state': 42,
'verbose': -1 # 不输出训练日志
}
model = lgb.LGBMRegressor(**params)
model.fit(X_train, y_train)
6.1、关键参数说明
max_depth = 5
树的最大深度。太深容易过拟合,太浅又学不到复杂规律。5是金融噪声数据的平衡点——更深的树在训练集上看起来更好,但测试集RankIC反而会下降。
learning_rate = 0.05
学习率,控制每棵树的贡献。
- 学习率高(0.1+):训练快,但容易震荡
- 学习率低(0.01-):训练慢,但更稳定
通常配合 n_estimators 一起调:
- learning_rate 小 → n_estimators 大
- learning_rate 大 → n_estimators 小
我选了0.05,中等速度。
bagging_fraction = 0.8 + feature_fraction = 0.8
每次训练只用80%的样本和80%的特征,增加随机性防止过拟合。类似随机森林的思想,让模型不过度依赖某几个特征,学到的规律更通用。
七、训练过程
predictor = StockPredictor(model_type='lightgbm')
# 1. 截面标准化
rank_cols = feature_cols + [target_col]
df[rank_cols] = df.groupby('date')[rank_cols].rank(pct=True)
# 2. 准备数据
X_train, X_test, y_train, y_test = predictor.prepare_data(
df, feature_cols, target_col='target_return_5d', test_size=0.2
)
# 3. 训练模型
predictor.train(X_train, y_train)
# 4. 预测
y_pred = predictor.predict(X_test)
输出:
截面标准化...
✓ 完成
训练集: 1,230,130 样本
测试集: 307,533 样本
训练LightGBM模型...
参数: {'objective': 'regression', 'max_depth': 5, ...}
✓ 模型训练完成
八、模型评估
量化领域评估预测模型用的是这套体系:
# 基础误差(逐样本)
mae = mean_absolute_error(y_test, y_pred)
# RankIC / ICIR(截面,量化核心)
# 每个交易日:计算当日所有股票的预测排名与实际收益排名的相关性
for date, group in test_df.groupby('date'):
rank_ic, _ = spearmanr(group['pred'], group['target'])
icir = rank_ic_arr.mean() / rank_ic_arr.std() # 信号稳定性
各指标含义:
- RankIC(Rank Information Coefficient):每日截面上,预测值排名与实际收益排名的 Spearman 相关系数,再对所有交易日取均值。直接回答"模型对强弱股票的区分能力如何"。>0.03 有效。
- ICIR:RankIC 均值 / RankIC 标准差。RankIC 高但忽正忽负没有意义,ICIR 衡量信号是否持续稳定。>0.5 稳定,>1.0 优秀。
8.1、我的模型效果
RankIC: 0.0370 (>0.03 有效)
ICIR: 0.2394 (信号持续稳定)
怎么理解这些数字?
- RankIC = 0.037:每天在 797 只股票里,按预测值排序与按实际 5 日涨跌幅排序,有 3.7% 的秩相关。股票市场噪声极大,能稳定维持正相关是有效信号。
- ICIR = 0.24:信号存在一定波动,部分时间段(如市场风格剧烈切换时)IC 会下降。但从季度维度看,测试集 7 个季度 IC 全部为正,说明信号方向持续正确。
8.2、分层回测:最直接的经济意义
IC 数字对非量化背景的人不直观,分层回测更好理解。
把每个交易日的预测值从低到高分成 5 组,看各组的实际平均收益:
Q1(预测最差): +0.108%/天
Q2 : +0.252%/天
Q3 : +0.294%/天
Q4 : +0.317%/天
Q5(预测最好): +0.386%/天
多空价差(Q5-Q1): 0.278%/天 → 年化 69.5%
Q5 日均收益是 Q1 的 3.6 倍,从最差到最好单调递增,说明模型对强弱股票的区分能力是真实的。
重要提示:这是理论上的模型区分能力,不代表实盘收益
年化69.5%的"多空价差"听起来很诱人,但这是理想化的理论指标,实盘中无法实现。原因:
1. 交易成本会吞噬大部分收益
- 双边交易成本:佣金(0.03%) + 印花税(0.1%) + 滑点(0.1-0.2%) ≈ 0.3%/次
- 每日调仓(250个交易日):年化成本 = 250 × 0.3% =75%
- 69.5%的理论收益会被成本吃掉大部分
2. A股卖空限制
- 融券困难:可融券标的少,费率高(年化5-10%)
- "多空价差"策略在A股只能做多头(买Q5,不能卖空Q1)
- 实际可用的只是Q5的绝对收益(+0.386%/天 = 年化96.5%)
- 扣除交易成本后:96.5% - 75% =21.5%
3. 流动性和冲击成本
- Q5组可能包含小盘股、ST股等流动性差的股票
- 大资金配置会产生严重的冲击成本(实际成交价偏离理论价)
- 冲击成本随资金规模增长:1000万可能0.5%,1亿可能2-3%
4. 其他实盘约束
- 停牌、涨跌停限制导致无法成交
- 策略容量限制(资金过大后收益下降)
- 模型衰减(市场环境变化导致效果下降)
这个指标的真正意义:
- 不是"我能赚69.5%",而是"模型能持续区分强弱股票"
- 如果模型区分能力存在,扣除所有成本后仍可能有盈利空间
- 用于评估模型质量,而非预测实盘收益
8.3、时间稳定性
按季度看 IC 趋势:
2023Q2: +0.037 ██████████████████
2023Q3: +0.091 █████████████████████████████████████████████
2023Q4: +0.030 ███████████████
2024Q1: +0.005 ██
2024Q2: +0.014 ██████
2024Q3: +0.043 █████████████████████
2024Q4: +0.091 █████████████████████████████████████████████
IC>0 季度占比: 100%
7 个季度全部为正,信号方向持续正确。2024Q1 偏弱(0.005)对应 A 股当时的极端行情,模型在风格剧烈切换时信号减弱,符合真实市场特征。
九、特征重要性分析
截面标准化后的特征重要性:
【Top 10 重要特征】
feature importance
return_1d 299
price_position 281
macd 261
atr_60d 260
volatility_5d 247
volatility_20d 238
volatility_60d 230
atr_20d 227
macd_signal 224
volume_ratio_20 220
关键洞察:
- 短期反转效应显著
return_1d(昨日收益)是最重要特征(299)- 说明A股存在明显的短期反转:昨天涨的今天可能跌,昨天跌的今天可能涨
- 这是市场非理性情绪导致的过度反应和随后的修正
- 波动率指标占据半壁江山
- Top 10中有5个波动率相关指标(
atr_*,volatility_*) - 说明相对波动水平对预测5日收益有很强的区分度
- 高波动股票在趋势行情中涨得更猛(高贝塔效应)
- 低波动股票在震荡市中表现更稳(防御属性)
- Top 10中有5个波动率相关指标(
- 技术指标的有效性
macd,macd_signal等经典技术指标仍然有效price_position(价格相对位置)排名第二,说明"追涨杀跌"有一定道理
- 与金融学理论的契合
- 短期反转(1日):行为金融学的过度反应假说
- 中期动量(5-20日):价格延续效应
- 波动率因子:风险定价理论(高风险高收益)
这些发现不仅验证了特征工程的有效性,也说明模型学到的是有金融学解释的真实市场规律,而非数据中的随机噪音。
十、交叉验证
为了验证模型的稳定性,保留了时间序列交叉验证代码:
def cross_validation_score(X, y, n_splits=5):
"""时间序列交叉验证"""
tscv = TimeSeriesSplit(n_splits=5)
for fold, (train_idx, val_idx) in enumerate(tscv.split(X), 1):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
...
TimeSeriesSplit 保证每次都用过去预测未来:
Fold 1: 训练[0:500] 验证[500:600]
Fold 2: 训练[0:600] 验证[600:700]
Fold 3: 训练[0:700] 验证[700:800]
...
交叉验证代码已保留在 predictor.py 中,可按需取消注释运行。从季度 IC 趋势(测试集 7 个季度全部为正)来看,模型的时间稳定性已经得到验证。
十一、模型保存与加载
# 保存模型
predictor.save_model('results/lightgbm_price_model.pkl')
# 加载模型
predictor = StockPredictor()
predictor.load_model('results/lightgbm_price_model.pkl')
# 预测
y_pred = predictor.predict(X_new)
用joblib保存,文件大小约10MB,加载速度很快。
十二、改进方向
当前模型仍有很大提升空间,以下是按优先级排序的改进方向:
12.1、特征层面(高优先级,ROI最高)
基本面因子:
- 加入财务指标:PE、PB、ROE、ROA、负债率
- 盈利质量:营收增长率、净利润增长率、现金流
- 估值因子往往比技术因子更稳定
行业和风格因子:
- 行业中性化处理:去除行业beta,专注选股能力
- 市值因子:大盘股、小盘股的不同表现
- 风格因子:成长、价值、质量
替代数据:
- 新闻情感分析(需要NLP)
- 社交媒体热度(东方财富、雪球)
- 研报观点(机构评级变化)
预期提升:
- RankIC可能从0.036提升到0.045-0.055
12.2、模型层面(中优先级,需权衡成本)
模型集成:
# 简单加权平均
pred = 0.5 * lgb_pred + 0.3 * xgb_pred + 0.2 * lstm_pred
# 或Stacking(用预测作为新特征)
meta_features = np.column_stack([lgb_pred, xgb_pred, lstm_pred])
final_pred = meta_model.predict(meta_features)
滚动训练/在线学习:
- 当前用固定的80/20分割
- 改为滚动窗口:每天用过去2年数据训练,预测明天
- 更贴近实盘,但计算成本高
多目标预测:
- 同时预测收益和波动率
- 或预测不同时间尺度(1日、5日、20日)
预期提升:
- RankIC可能提升0.003-0.008(约10-20%)
12.3、数据层面(长期方向)
扩展股票池:
- 当前795只,可扩展到全A股3000+
- 但需要处理小盘股流动性问题
提高数据频率:
- 从日频到分钟频(需要高频数据源)
- 捕捉盘中微观结构信息
更长的历史数据:
- 当前3年,可扩展到10年
- 覆盖更多市场周期(牛熊转换)
十三、总结
预测模型这块主要内容:
数据规模:
- 输入:148万条特征数据,39个特征
- 训练集:前80%(约123万条,2015-2023年)
- 测试集:后20%(约31万条,2023-2024年)
技术选型:
- 对比了三个模型:XGBoost、LightGBM、LSTM
- LSTM效果最好:RankIC = 0.0415(最高),但训练时间慢5.6倍
- XGBoost效果略优于LightGBM:RankIC高0.0015(0.0377 vs 0.0362)
- 最终选择LightGBM:速度快1.7倍,效果相当,工程成本低
- 决策依据:在日频场景,速度优势 > 0.15%的IC差距
关键处理:
- 截面标准化:每日对所有股票做特征排名,消除绝对值跨股票不可比问题
- 时间序列分割:前80%训练,后20%测试,不随机打乱
- 特征和目标同步排名:保证模型学习目标与评估指标一致
评估指标:
- RankIC = 0.037(过 0.03 有效阈值)
- ICIR = 0.24(信号持续稳定)
- Q5-Q1 年化价差 = 69.5%(区分强弱股票能力显著)
- 7 个季度 IC 全部为正
下一篇: 第5篇:运筹优化